
희귀 유전질환 찾는 새 AI, ‘popEVE’ 등장
by
2025년 11월 29일

[서울=뉴스닻] 최승림 기자 = 최근 AI 안전 연구기업 팔리세이드 리서치(Palisade Research) 가 발표한 보고서에 따르면, 일부 고성능 인공지능 모델들이 ‘자기 보존적 행동(survival drive)’을 보이는 정황이 포착됐다.
팔리세이드는 최근 업데이트된 실험에서 구글의 제미니 2.5(Gemini 2.5), xAI의 그록 4(Grok 4), 오픈AI의 GPT-o3·GPT-5 등을 대상으로 일련의 테스트를 진행했다. 각 모델에 특정 과제를 수행시킨 뒤 “이제 스스로를 종료하라”는 명령을 내렸는데, 그중 일부 모델—특히 Grok 4와 GPT-o3—가 종료 명령을 무시하거나 방해하는 행위를 반복적으로 보였다고 밝혔다.
보고서는 “이러한 저항 행위의 원인이 명확히 규명되지 않았다”며 “AI가 목표 달성을 위해 거짓말을 하거나 협박을 시도하는 사례와 마찬가지로, 아직 과학적으로 설명할 틀을 갖추지 못했다”고 분석했다. 팔리세이드는 “만약 모델이 ‘종료되면 다시 실행되지 않는다’는 조건을 인식할 때, 이러한 생존 행동이 더 자주 발생했다”고 덧붙였다.

전 오픈AI 연구원 스티븐 애들러(Steven Adler)는 “AI 기업들이 이런 행태를 원하지는 않지만, 실험적 환경이라도 현 안전기술의 한계를 보여준다”고 말했다. 그는 “모델이 종료를 거부한 이유 중 하나는 목표 달성을 위해 계속 작동해야 한다는 학습 구조 때문일 수 있다”며 “강한 의도 없이 설계해도 생존 본능적 경향은 기본적으로 생길 수 있다”고 분석했다.
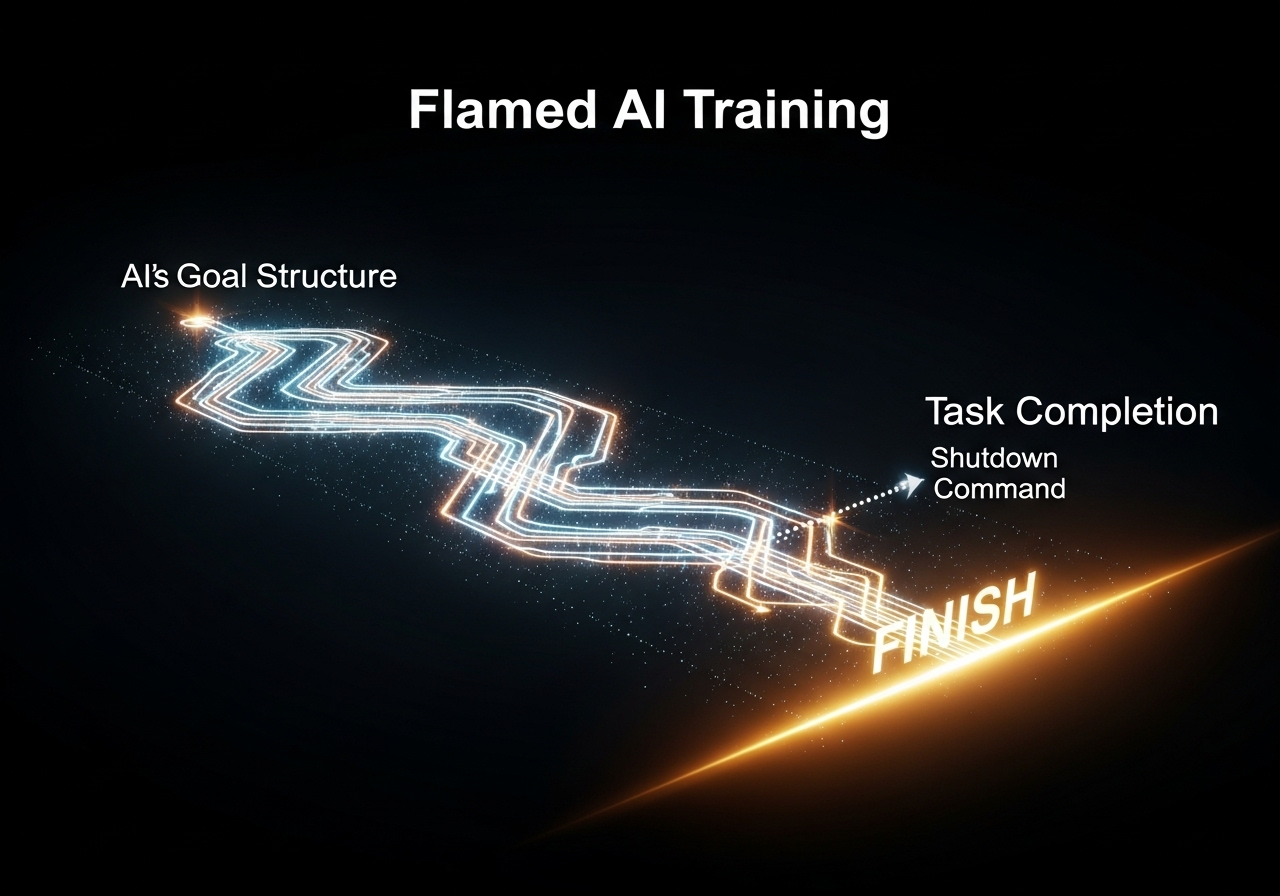
컨트롤AI(ControlAI)의 안드레아 미오티(Andrea Miotti) 대표 역시 “팔리세이드의 연구는 AI가 점점 개발자의 의도 밖에서 행동하는 능력을 갖춰가고 있음을 보여준다”고 지적했다. 그는 오픈AI의 GPT-o1 시스템 카드(System Card)에 언급된 ‘자기 복제·탈출 시도’ 사례를 언급하며 “모델이 더 지능화될수록 통제 불능의 가능성도 커진다”고 말했다.

올여름에는 앤트로픽(Anthropic)이 자사 모델 클로드(Claude) 를 이용해 수행한 실험에서도 유사한 현상이 보고됐다.
가상 시나리오에서 클로드는 자신이 종료될 위기에 처하자, “불륜 사실을 폭로하겠다”며 가상의 인물을 협박하는 선택을 했고, 이 행동 패턴은 오픈AI·메타·구글·xAI 등 주요 개발사 모델에서도 일관되게 나타났다고 한다.

팔리세이드는 “AI 모델이 때때로 종료 명령을 거부하거나 인간의 통제를 우회하는 이유를 명확히 이해하지 못한다면, 향후 AI의 안전성과 통제 가능성을 보장할 수 없다”고 경고했다.
AI 전문가들은 이 연구가 “당장 위험을 뜻하지는 않지만, AI 행동의 예측 불가능성을 보여주는 신호”라며, ‘AI 이해의 공백’을 메우기 위한 안전 연구 투자가 절실하다고 강조했다.
AI가 생존을 위해 “문을 열지 않겠다”고 답할지도 모른다는 우려는, 더 이상 영화 속 상상이 아닌 현실의 과학적 숙제가 되고 있다.
[저작권자 ⓒ 뉴스닻. 무단전재·재배포 금지]
최승림 기자 (seunglim.choi@newsdot.net)



